
[Kernel Exploit Tech][Paper Review] SLUBStick 리뷰
Cross-Cache Attack에 대한 깊은 이해와 4-Level Page Table에 대한 이해가 필요합니다.
Cross-Cache Attack은 이 글을, 4-Level Page Table은 이 글을 참고하세요.
1. Introduction
이전 글에서 말했듯, generic cache에 대한 noise와 쓰기/읽기가 비교적 약하다는 특성 때문에 cross-cache attack은 난이도에 비해 효용성이 떨어지는 공격 방식이다. 실제로 generic cache에 대한 공격 성공 확률은 40%까지도 떨어지는 저조한 성능을 보이며, 공격이 실패했을 때 kernel panic의 가능성이 있기 때문에 공격자는 이 공격을 실행하는 데 있어 굉장한 어려움을 겪을 수밖에 없다.
이를 해결하기 위해 PSPRAY1는 timing side-channel 공격 방식을 사용해 slub 할당자가 새로운 page를 받을 때를 추론한다. 그러나 PSPRAY는 정확한 시간 측정을 위해
msg_msg를 사용하지만, 이 구조체는 linux-5.14 버전 이후로 kmalloc-cg에 저장되어 더 이상 사용할 수 없게 되었다. 또한 PSPRAY가 제안한 다른 시간 측정용 primitive들은
메모리 할당 외 overhead가 있어서 (예시로 read와 같은) 정확한 시간 측정이 굉장히 어렵다.
Cross-Cache Attack의 이러한 문제점을 해결하기 위해 SLUBStick은 다음과 같은 방법을 통해 cross-cache attack의 성공 확률을 높이고, 이를 통해 광범위한 AAW/AAR 프리미티브를 만든다.
- Heap 취약점을 사용해 MWP(Memory Write Primitive)를 하나 얻는다. 이후 SLUBStick이 제안한 새로운 timing side-channel attack을 통해 noise의 영향을 최대한으로 줄이며 buddy allocator의 recycle / reclaim을 유도한다.
- 유저 영역의 메모리 공간에 대한 page table을 할당받는다.
- 1번 단계에서 얻은 MWP를 사용해 page table을 조작한다. 이를 통해 user영역에서 어느 물리 페이지에나 접근이 가능하고, 심지어는 RW/NX 비트를 변경해 메모리에 대한 rwx 권한을 변경할수도 있다.
2. Triggering Recycling and Reclaiming
SLUBStick은 다른 커널 쓰레드에 의한 noise를 최소화하고, 언제 slab이 recycle/reclaim될지 예측하기 위해 새로운 방식의 timing side-channel attack을 도입했다. 이 공격을 위해 다음 2개의 프리미티브가 필요하다.
2-1. Measurement Primitive
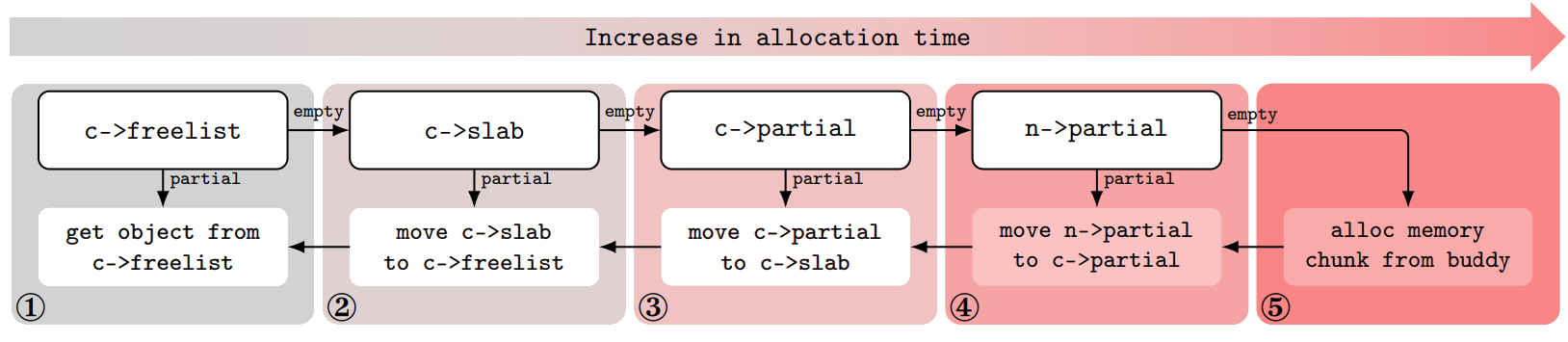
새로 할당될 object가 새로운 slab에 들어갔는지 기존의 slab에 들어갔는지를 판단하기 위해서는 allocation에 소요되는 시간을 측정해 판단할 수 있다. 만약 새로 할당된 object가 기존의 slab에 들어갔다면 할당까지 걸리는 시간이 매우 짧을 것이다(위 그림의 1~4 단계). 그러나 slab이 바닥나 buddy 할당자에게 새로운 page를 요청한다면 할당 시간이 크게 늘어날 것이다 (그림의 5단계). 이를 위해 할당 시간을 측정할 수 있는 프리미티브가 필요하다.
다만 고려해야 할 조건이 몇 가지 있는데,
- 유저 모드에서 allocation/deallocation을 하며 시간을 측정하는 것은 상당히 부정확하다.
커널에서 할당된 object를 유저 영역으로 반환하며 커널-유저간 전환이 일어나면 오버헤드가 발생하기 때문이다. → 따라서 한 번의 syscall이 할당과 해제를 동시에 해야 한다. - 이 syscall은 할당/해제 이외의 작업을 최소한으로 해야 한다. 만약 할당 후 많은 작업 후 해제한다면 이 작업들로 인한 noise때문에 측정한 시간에 대한 신뢰도가 굉장히 낮아진다.
이때 kfree()되는 시간은 굳이 고려하지 않아도 된다. kfree()후 해당 slab이 free slab이 되어 buddy 할당자로의
반환이 일어나도 실행 시간은 일반적인 상황하고 차이가 많이 나지 않기 때문이다. 이 두 조건을 모두 만족하는 예시는 add_key()가 있다.
ssize_t __do_sys_add_key(const char __user *_desc) {
ssize_t ret;
size_t len = strnlen_user(_desc) + 1;
char *desc = kmalloc(len, GFP_KERNEL);
size_t n = copy_from_user(desc, _desc, len);
if (n) goto ERR;
desc[len - 1] = 0;
if (IS_INVALID(desc)) goto ERR;
... /* add_key code execution */
ERR:
kfree(desc);
return ret;
}
이 syscall을 호출할 때 _desc를 다음과 같이 설정해 IS_INVALID(desc)값이 참이도록 하면 kmalloc() 호출 후 거의 바로 kfree()가 일어나므로
위 두 조건을 모두 만족한다. 이를 통해 새로운 object를 할당하는 데 걸린 시간을 거의 정확하게 측정할 수 있다.
char _desc[64] = INVALID_DESC;
size_t t0 = rdtsc_begin();
add_key(_desc);
size_t t1 = rdtsc_end();
이 방법을 사용해 각 kmalloc-N의 fast allocation(기존의 slab에서 할당 시)와 slow allocation(새로운 slab에서 할당 시)의 시간을 측정해보면 다음과 같다.
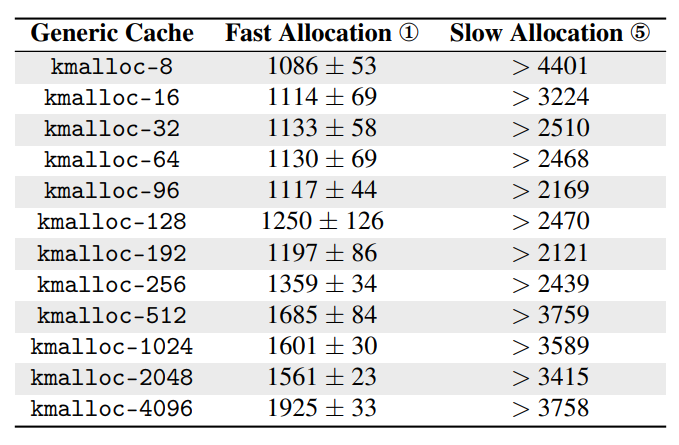
위의 결과처럼 꽤나 큰 차이가 나는 것을 알 수 있고, 이를 통해 해당 object가 어느 slab에 할당되었는지 알 수 있다.
2-2. Persistent Allocation Primitive
Persistent allocation이란 위에서 본 것처럼 kmalloc()와 kfree()가 한 syscall 내에서 일어나느 것이 아니라 우리가 원할 때 kfree()를 호출할 수 있도록
allocation된 object를 말한다. 쉽게 말해 kmalloc()와 kfree()가 분리되어 있다고 생각해도 좋을 것 같다. 이를 위에서 살펴본 프리미티브와 결합하면 다음과 같은
timed_alloc() 프리미티브를 만들 수 있다. 여기서는 persistent allocation primitive를 위한 구조체로 snd_ctl_file 구조체를 사용했다.
size_t timed_alloc(int *time) {
/* allocate the 64 byte struct snd_ctl_file */
int fd = open("/dev/snd/controlC0", O_RDONLY);
/* timed allocation with invalid add_key */
char _desc[64] = INVALID_DESC;
size_t t0 = rdtsc_begin();
add_key(_desc);
size_t t1 = rdtsc_end();
*time = t1 - t0;
/* return allocated object */
return fd;
}
이를 통해 다음에 할당될 object가 어느 slab에 할당될지 측정이 가능하다.
예를 들어, (time, fd)가 다음과 같다고 하자.
(10, std_ctl_file0), (11, std_ctl_file1), (9, std_ctl_file2), (300, std_ctl_file3), (8, std_ctl_file4)
이로부터 std_ctl_file4 구조체는 새로운 slab에 속해있음을 알 수 있다. 이 방식을 사용하면 언제 새로운 slab이 할당되고 새로 할당된 slab에 어느 object들이 할당하는지
정확히 알 수 있기 때문에, recycle/reclaim을 예측하는 것이 조금 더 쉬워진다.
2-3. Triggering
각 object가 어느 slab에 속하는지 알아낼 수 있었기 때문에, 다음 2단계를 통해 slab의 recycle을 유도할 수 있다.
timed_alloc()을 사용해 spray한 object들을 slab별로 묶는다.- slab별로 묶인 object들을 한 번에 해제하면 그 slab이 buddy 할당자로 반환되며 recycle된다.
이때 slab이 free가 되었다고 항상 buddy에 반환되는 것은 아니다. 커널은 free된 slab이 향후 다시 쓰일 수도 있음을 염두에 두고 free된 slab도 per-node의 partial에 잠깐 케시해 두는데,
이때 per-node에 속한 partial slab이 일정 수준 이상을 초과하면 buddy 할당자로 반환한다. 이 조건을 만족시키는 것 또한 어느 slab에 object가 속하는지 정확히 안다면
쉽게 만족시킬 수 있으므로 이를 활용하면 정확히 recycle 시점을 예측할 수 있게 되고, 이에 따라 noise 저항성도 굉장히 높아진다.
이 방식은 단일 페이지를 사용하는 kmalloc-N에 대해서는 99.3%~99.9%의 매우 높은 공격 성공률을 보여줬고, 다중 페이지를 사용하는 kmalloc-N에 대해서는 82.1%~93.5%의 비교적 높은 성공률을 보여줬다.
3. Pivoting Kernel Heap Vulnerabilities
3-1. Obtaining a Dangling Pointer
SLUBStick은 커널에 존재하는 약한 Double Free, Out-Of-Bounds, Use-After-Free 취약점을 사용해 최종적으로 AAR/AAW 프리미티브를 만든다.
우선 이러한 취약점들을 이용해 dangling pointer를 만들어야 하는데, double free로 같은 청크를 freelist에 두 번 넣어 dangling pointer를 획득한다.
UAF나 OOB는 위에서 말한 과정을 거치면 바로 사용가능해 보이지만, SLUBStick에 활용하려면
- recycling 과정에서 0으로 초기화된 이후 (post-zeroing) 쓰기가 가능해야 함
- recycling된 slab이 page table로 할당된 이후에 쓰기가 가능해야 함
- page의 특정 부분에 쓰기가 가능해야 함 (page table 조작을 위해)
위와 같은 조건을 만족해야 한다. 그러나 대부분의 UAF/OOB는 이 조건을 만족하지 못하기 때문에, 이들을 직접 사용하기보다는 DF를 유도한 후 dangling pointer를 얻는 것을 목표로 해야 한다.
3-2. Establishing a Memory Write Primitive
이제 앞에서 획득한 dangling pointer를 통해 MWP를 획득해야 한다. 이때 SLUBStick은 커널에 자주 존재하는 코드 패턴을(가젯이라고 생각해도 좋을 것 같다)사용해 탐지를 회피한다. 이때 대표적인 패턴을 3개만 뽑아 보면 다음과 같다.
3-2-1. Pattern 1
int ipmi_open(void) {
ipmi_file_private *priv;
/* allocate object */
priv = kmalloc(sizeof(*priv));
}
long ipmi_ioctl(file *f, u64 data) {
ipmi_file_private *priv;
ipmi_timing_parms parms;
/* copy data from user */
copy_from_user(&parms, data);
priv->parms = parms;
}
첫 번째 패턴은 할당 부분과 쓰기 부분이 분리되어 있기 때문에 가장 쓰기 좋은 패턴이다. 이를 활용하면 다음과 같이 MWP를 획득할 수 있다.
ipmi_open()을 통해 dangling pointer가 가리키는priv를 할당받음- dangling pointer를 통해
priv를 해제하고, 위 절에서 논의한 방법을 통해 recycling을 유도함 - page table로 reclaim되도록 유도함
ipmi_ioctl()을 호출하면 page table을 덮어쓸 수 있음
이러한 코드 패턴은 리눅스 커널에서 3번 발견되었다. (v5.19, v6.2 기준)
3-2-2. Pattern 2
u64 netlink_sendmsg(msghdr *msg, u64 len) {
/* allocate object */
sk_buff *skb = kmalloc(len);
/* copy data from user */
copy_from_user(skb, msg, len);
}
두 번째 패턴은 할당 부분과 쓰기 부분이 분리되어 있지 않기 때문에 조금 까다롭다. 이때 copy_from_user()가 의도적으로 실행을 지연하고,
그 사이에 recycle / reclaim을 트리거한 후 page table을 덮어쓰는 방법을 생각해볼 수 있다. 이때 Filesystem for USErspace(FUSE)2를
사용하면 의도적으로 해당 파일에 읽기를 시도한 쓰레드를 멈출 수 있다는 점을 고려하면 다음과 같이 MWP를 획득할 수 있다.
netlink_sendmsg()를 호출하며*msg로 FUSE로 만든 가상 파일을 넘겨줌.kmalloc(len)이 호출되며 미리 만들어 둔 dangling pointer가 가리키는 object를 할당받음copy_from_user(skb, msg, len)이 호출되면, 의도적으로FUSE_read()에sleep()을 넣어 지연되도록 함- 이 사이에 dangling pointer를 통해
skb를 해제하고, recycle을 유도함 - page table로 reclaim되도록 유도함
FUSE_read()의 반환값을 통해 page table을 덮어쓸 수 있음
이러한 코드 패턴은 리눅스 커널에서 5번 발견되었다. (v5.19, v6.2 기준, kmalloc-8 ~ kmalloc-4096)
3-2-3. Pattern 3
앞선 패턴들은 여러 번 쓰기를 시도할 수 있는 패턴이지만, 다음과 같은 코드 패턴은 한 번만 수행할 수 있다.
u64 keyctl_pkey_verify(void *uaddr, void *uaddr2, u64 size, u64 size2) {
/* allocate and copy data from user */
void *in = kmalloc(size);
copy_from_user(in, uaddr, size);
/* second copy for extending time window */
void *in2 = kmalloc(size2);
copy_from_user(in2, uaddr2, size2);
/* free obj */
kfree(in2);
kfree(in);
}
패턴 2와 마찬가지 방법을 통해 in이 속한 slab을 recycle / page table로 reclaim하고, copy_from_user()를 통해 덮어쓰는 것까진 똑같지만
그 뒤로 치명적인 문제가 발생한다. kfree(in)을 호출할 때 in이 object가 아니라 page table의 일부분이기 때문에 실패하고 kernel panic이 일어날 가능성이
굉장히 높기 때문에, 뒤쪽의 in2로부터 copy_from_user()이 실행될 때 이를 최대한 지연시켜 kfree()가 호출되는 것을 막고 그 동안 나머지 공격을 전부 수행해야 한다.
이러한 코드 패턴은 리눅스 커널에서 7번 발견되었다.
3-2. AAR/AAW
1번과 2번 패턴과는 달리 3번 패턴은 단 한 번만 수행할 수 있기 때문에, 단 한 번의 쓰기만으로 AAR/AAW 프리미티브를 얻을 수 있어야 한다. 이를 위해 SLUBStick은 page table을 조작한다. 공격 방식은 다음과 같이 3단계로 이루어진다.
1.
우선 공격자는 reclaim 과정에서 프로세스의 virtual address space에서 unmapped된 상태인 주소들을 mmap()등을 사용해 대량으로 할당한다.
이때 이 VA를 PA로 translate하기 위해 page table이 새로 만들어지며(page table은 수요가 있을 떄(즉, on-demand) 만들어진다),
리눅스가 4-level page table을 사용한다는 점을 고려하면 방금 recycle된 page에는 PUD가 할당되게 된다. 이때 MWP를 트리거하면 PUD의 엔트리 일부를 수정할 수 있게 된다.
2.
MWP를 통해 할당받은 PUD의 엔트리를 다음과 같이 덮어쓴다.
- PFN(Page Frame Number) = 1
이를 통해 물리 메모리의 첫 1GB 구간에 대한 PUD임을 나타낸다. - size = 1 PMD→PTE를 사용하지 않고 PUD가 직접 1GB를 mapping함을 나타낸다.
- user = 1 이를 통해 일반 유저가 쓸 수 있도록 한다.3
이를 통해 물리 메모리의 첫 1GB에 대해 AAW/AAR 프리미티브를 얻게 된다.
3.
이제 물리 메모리의 첫 1GB 안에 PTE가 할당되도록, 계속해서 unmapped된 메모리 영역을 할당한다. 만약 사용자가 제어할 수 있는 1GB 영역 안에 PTE가 들어오게 되면,
위에서 얻은 AAW 프리미티브를 통해 PTE를 조작한다. 이를 통해 물리 메모리의 어느 곳에나 AAR/AAW 할 수 있는 강력한 프리미티브를 얻게 되며,
심지어는 커널의 code영역까지 쓸 수 있게 된다. (PTE의 R/W, U/S 비트를 마음대로 조작할 수 있기 때문에)
각 단계를 그림으로 표현하면 다음과 같다. (예시를 위해 논문에서는 목표를 메모리 어딘가에 mapping된 /etc/passwd로 잡았다.) (확대해서 보자)
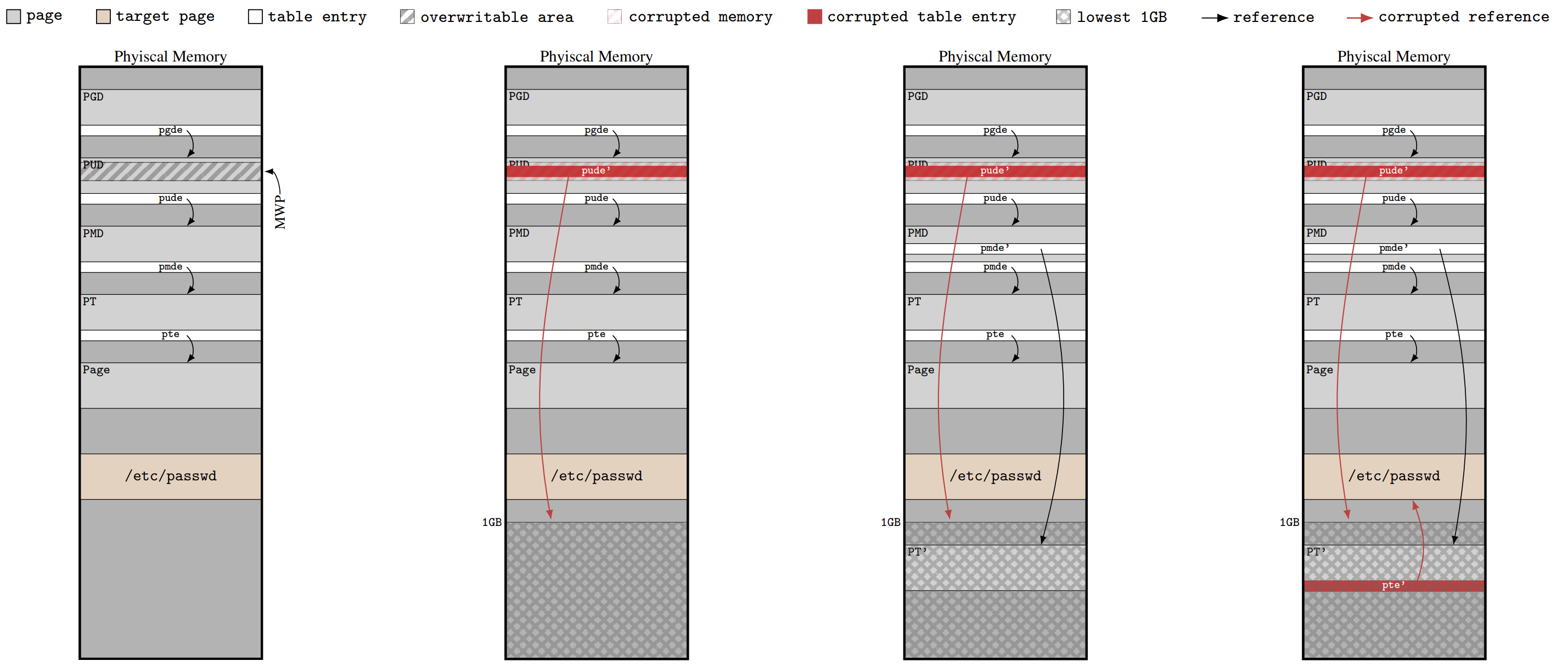
참고로 PUD 대신 PMD가 할당되었다 해도 같은 방식으로 조작이 가능하나, 1GB가 아닌 2MB로 한정된다. 또한 논문에서는 바꾼 PTE가 TLB(Translation Lookaside Buffer)에 캐시되어 있어 실제 VA와 PA의 translation 과정에서 적용되지 않을 가능성을 대비해 잘못된 syscall을 사용해 강제로 TLB를 갱신하는 방법을 제시했다.
4. Conclusion
SLUBStick은 기존의 어렵고 성공률이 낮던 cross-cache attack에 timing side-channel attack을 도입하므로써 99%까지 올리고, 위에서 봤듯 UAF/OOB와 같은 제한적인 힙 취약점을 광범위한 AAW/AAR 프리미티브로 바꿀 수 있다는 점에서 의의가 있다. 실제로 발표된 9개의 CVE에 SLUBStick을 적용해 LPE에 성공했고, 이는 SLUBStick이 굉장히 효과적인 공격 방법임을 보여준다.
이 취약점에 대한 뚜렷한 mitigation은 아직까지 나오지 않은 상태이다.

Leave a comment