
[Kernel Analysis] MM - Slub Allocator 분석
Buddy Allocator에서 이어지는 글입니다.
이전 글을 먼저 읽고 이 글을 읽는 것을 추천합니다.
이전 글의 마지막 절에서 언급했듯, 만약 커널에서 지원하는 메모리 할당의 최소 단위가 page라면
수 바이트의 구조체를 동적으로 할당할 때 4KB의 메모리 할당이 일어나므로 내부 단편화(internel fragmentation)를 피할 수 없다. 실제로 커널은 dentry, mm_struct, inode 다양한 크기의
많은 구조체를 자주 할당하고 해제하는데, 이를 위해 한 페이지 전체를 할당받고 반환하는 것은 무척 비효율적인 일일 것이다. 따라서 커널은 page 단위보다 작은 단위의 할당자가 필요한데,
이를 위해 사용되는 것이 Slab Allocator이다. Slab 할당자는 slab, slub, slob 할당자로 이루어저 있는데,
이번 글에서는 현대 리눅스 커널에서 기본적으로 사용하는 slub 할당자를 중심으로 분석했다.
1. slub 할당자의 필요성
위에서 언급했듯, slub 할당자는 page 단위보다 작은 메모리 할당을 목표로 한다. 이를 위해 커널에서는 일반적으로 userland의 malloc()와 같이 원하는 만큼의 메모리 할당을 위해 kmalloc()를 사용하며,
kmalloc()는 내부적으로 slub 할당자를 사용한다. 이렇게 원하는 만큼의 메모리 할당을 위해 slub 할당자는 다음과 같이 동작한다.
- 우선 buddy 할당자로부터 page 단위의 메모리를 할당받는다. (이제부터 이 page는 slab이라 부른다)
- 각
slab은 미리 지정된 사이즈에 맞게 분할되며, 이들은freelist에 연결되어 관리된다.
(이렇게 잘린 메모리 조작을 object라 부른다. heap의 chunk라고 생각하자.) kmalloc()가 호출됐을 때 요청된 사이즈보다 작지 않은 object를 찾아 할당한다.
여기서 주목해야 할 것은 3번 사실이다. 다시 말하면, slub 할당자를 사용하는 kmalloc()는
함을 보장한다는 것이고, 이것이 userland의 malloc()와 비교했을 때 가장 큰 차이점이다.
2. kmalloc-N
위에서 살펴봤듯 kmalloc()는 할당받은 page를 미리 지정된 크기대로 분할해 object를 만든다. 이를 위해 kmem_cache 구조체를 사용하는데, 이 구조체의 원형은 다음과 같다.
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* The size of an object including metadata */
...
struct kmem_cache_node *node[MAX_NUMNODES];
...
}
여기서 object를 관리하는 것은 kmem_cache_cpu 구조체와 kmem_cache_node 구조체이다. 이때 kmem_cache_cpu 구조체는
어느 CPU가 접근하느냐에 따라 알아서 그 값이 바뀌는 멤버이다. 이들 구조체는 뒤에서 더 자세히 살펴보자.
kmem_cache 구조체에서 중요한 멤버 변수는 size이다. 이는 해당 캐시가 가진 object들의 크기를 의미하는 변수이다.
앞서 말했듯 slub 할당자의 캐시는 userland의 bins와 달리 항상 같은 크기를 가진 object들만을 가진다. 기본적으로 kmalloc는 8부터 4096까지의 2의 제곱수를 캐시의 사이즈로 갖는데, 각 캐시를 일반적으로
kmalloc-N이라 부른다. 예를 들어,
kmalloc-8은 8바이트 크기의 object를 가진 cache임.kmalloc-16은 16바이트 크기의 object를 가진 cache임.
- kmalloc-4096은 4096바이트 크기의 object를 가진 cache임.
즉 900 바이트 크기의 메모리 할당을 kmalloc()를 통해 요청하면 커널은 자동적으로 이와 가장 같거나 큰 크기의 kmalloc-1024에서 찾아 할당해준다.
마찬가지로 커널이 480 바이트 크기의 메모리 할당을 kmalloc()를 통해 요청하면 커널은 자동적으로 이와 가장 같거나 큰 크기의 kmalloc-512에서 찾아 할당해준다.
이것이 위에서 말한 slub 할당자가 요청한 사이즈보다는 크거나 같은 메모리를 할당한다는 말의 이유이다.
3. kmem_cache_cpu, kmem_cache_node
3-1. bank와 node
현대의 CPU는 다수의 코어를 가지고 있다. 이 코어들이 전부 같은 데이터 버스를 사용한다면 병목 현상이 굉장히 심할 것이다. 이를 막기 위해 각 코어가 사용하는 버스를 분리해뒀는데, 이 구조를 NUMA라고 부른다. NUMA의 이러한 특성 때문에 각 코어가 메모리에 접근하는 속도는 차이가 날 수밖에 없다(물리적 거리가 다름).
이때 리눅스에서 접근 속도가 같은 메모리의 집합을 뱅크(bank)라 부르고, 이를 표현하는 구조가 노드(node)이다. 즉
라고 이해하면 된다. 그림으로 표현하면 다음과 같다.
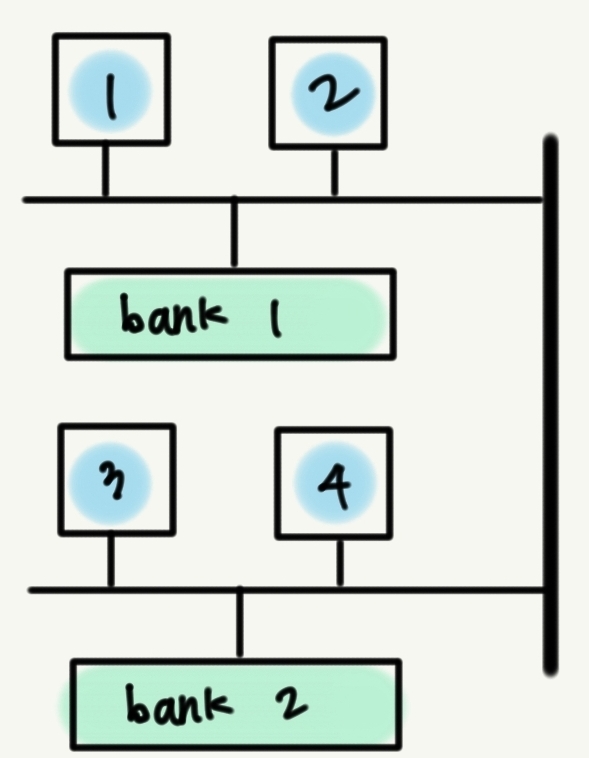
파란색으로 표현된 CPU 코어 1과 2는 초록색으로 표현된 bank 1에 속한 메모리에 접근하는 것이 가장 빠를 것이다. 마찬가지로 코어 3과 4는 bank 2에 속한 메모리에 접근하는 것이 가장 빠를 것이다.
3-2. per-node
위에서 잠깐 언급했던 kmem_cache_node 구조체의 정의를 살펴보면 다음과 같다.
struct kmem_cache_node {
spinlock_t list_lock;
...
unsigned long nr_partial;
struct list_head partial;
...
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
};
이 구조체는 같은 node에 속한 slab들을 관리한다. slub 할당자는 비어 있는 slab은 바로
버디 할당자로 반환하고 있기 때문에, partial과 full slab만을 추적한다. 여기서 partial slab이란 사용 가능한 객체들이 남이 있는 slab을 의미하며, full slab은
사용 가능한 객체가 하나도 남아있지 않은 slab을 의미한다. slub 할당자는 이들을 double linked list로 연결해 관리한다. 실제로 partial과 full이 가리키고 있는 구조체는 struct page로, 정의를 살펴보면 다음과 같다.
struct page {
...
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
...
}
...
}
위에서 말했듯 버디 할당자로부터 할당받은 page가 slub 할당자로 넘어오면 slab이라는 이름으로 불린다고 언급했던것 처럼, 둘은 같은 구조체를 쓰지만 공용체를 통해 내부 구조를
다르게 정의해둔 것을 볼 수 있다. 위에서 마지막 줄의 freelist는 현재 slab에서 할당이 가능한 object들을 single linked list로 연결해둔 것이다.
3-3. per-cpu
kmem_cache_cpu 구조체의 정의를 살펴보면 다음과 같다.
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
...
}
이 구조체는 위의 kmem_cache_node와 비슷하게 할당가능한 object를 single linked list로 연결해 둔 freelist를 멤버로 가진다. 그러나 kmem_cache_node와 가장 큰 차이점은 하나의 slab만을 가리킨다는 것이다.
그렇다면 왜 이런 구조체를 통해 단 하나의 slab만을 관리하는지 의문이 들 수 있는데, 여기서 기억해야 할 사실은 이때 위에서 말했듯 kmem_cache_cpu 구조체를 가리키고 있는 kmem_cache.cpu_slab은
는 것이다. 즉 이 구조체는 현재 사용 중인 CPU 코어에서 가장 빠른 node의 slab중 하나를 가리키고, 이를 통해 slub 할당자는 할당 요청이 들어왔을 때 kmem_cache_node.partial을 뒤질 필요 없이 빠르게 할당할 수 있다.
지금까지의 내용을 그림으로 정리하면 다음과 같다. 그림의 편의성을 위해 kmalloc-8, kmalloc-16만이 존재한다고 가정했다.
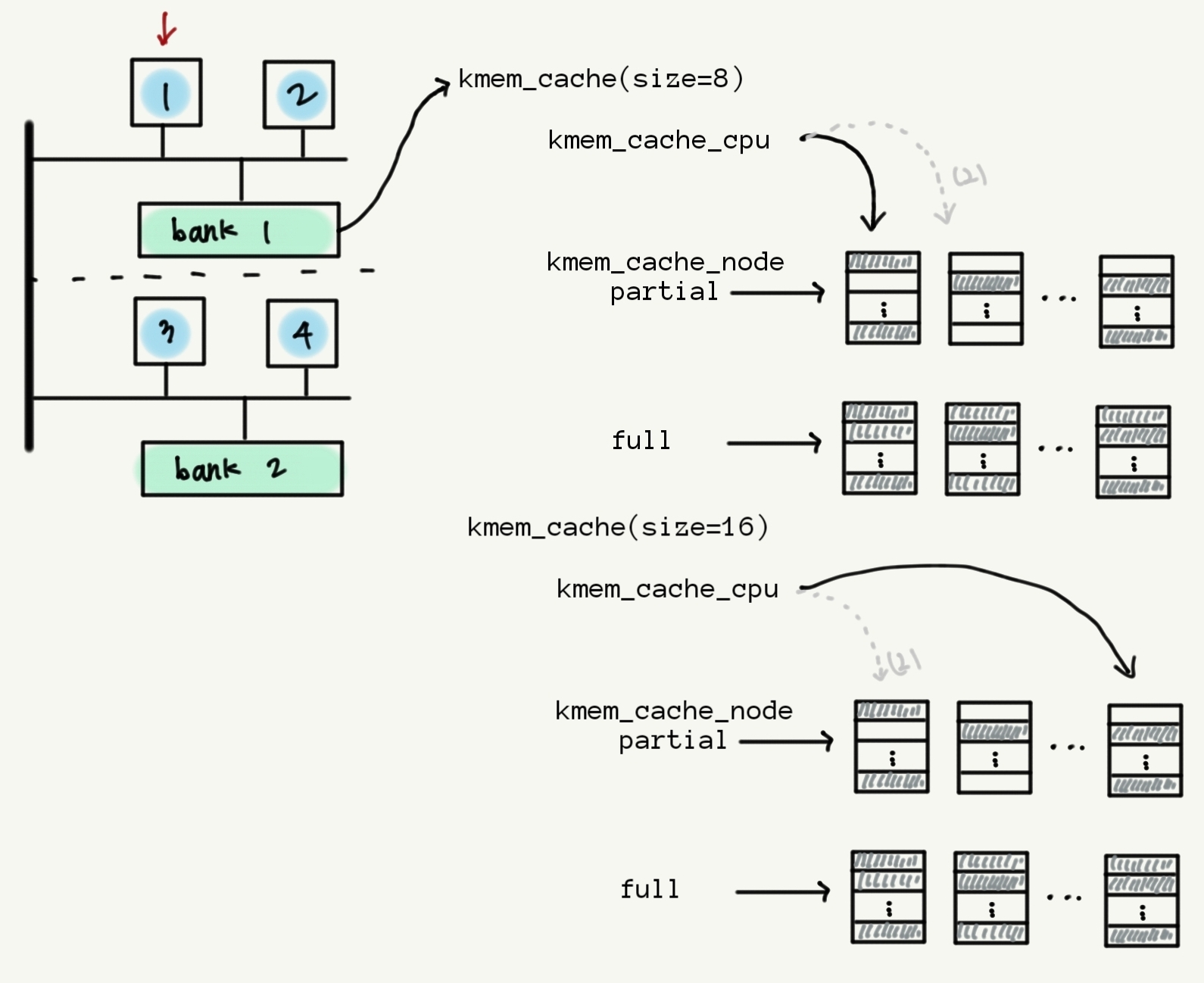
일반적으로 kmem_cache는 kmalloc-N의 개수만큼 존재한다. 위에서 든 예시에서는 8바이트 하나, 16바이트 하나만이 존재하므로 총 2개가 존재한다.
CPU 코어마다, node마다 존재하지 않아도 되는 이유는 kmem_cache_cpu와 kmem_cache_node가 어느 CPU에서 접근하냐에 따라 알아서 그 값이 변경되기 때문이다.
그러나 kmem_cache_cpu는 각 코어벌로 하나씩 존재한다. 이는 공간 낭비라고 생각할 수 있지만, 이런 방식을 사용하므로써 CPU1과 CPU2는 kmem_cache_cpu를 통해 slab에 접근할 때 별도의 lock을 설정하거나 해제할 필요가 없다.
그 시점에서 자신만이 해당 slab에 접근하고 있음이 보장되기 때문이다1.
만약 kmem_cache_cpu가 각 node별로 하나씩만 존재해 해당 노드에 속한 CPU가 같은 kmem_cache_cpu를 공유한다면 이를 사용해 slab에 접근할 때조차도 lock을 설정하고 해제하는 작업이 필요할 것이다.
4. stealing
4-1. 캐시된 partial
위에서 살펴봤듯 우선 커널은 per-CPU slab에서 최대한 메모리를 할당하려고 한다. 그러나 per-CPU slab이 full 상태여서 더 이상 할당할 수 없는 경우가 발생할 수 있는데, 이때 발생하는 것이 steal이다.
할당을 관리하는 함수인 ___slab_alloc를 살펴보면 다음과 같은 코드를 볼 수 있다.
if (!freelist) {
c->page = NULL;
c->tid = next_tid(c->tid);
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
...
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
...
만약 현재 cpu_slab에 freelist에 아무것도 없다면, 즉 slab이 full 상태라면 새로운 slab을 할당받는다. 이때 slub_percpu_partial()을 사용하는데,
이는 per-node에 접근하게 되면 slab에 lock을 거는 등 오버헤드가 필연적으로 발생할 수밖에 없기 때문에 미리 캐시해 둔 몇 개의 slab들 중 하나를 반환하는 함수이다.
4-2. 현재 node의 partial / 다른 node의 partial
그러나 이렇게 캐시해 둔 partial slab도 바닥날 수 있는데, 이를 대비한 코드는 다음과 같다.
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
여기서 호출하는 new_slab_objects()를 따라가면 다음과 같은 코드를 볼 수 있다.
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
...
}
여기서 호출되는 get_partial()을 한 번 더 따라들어가면
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct kmem_cache_cpu *c)
{
...
object = get_partial_node(s, get_node(s, searchnode), c, flags);
if (object || node != NUMA_NO_NODE)
return object;
return get_any_partial(s, flags, c);
}
위와 같이 get_partial_node()를 통해 현재 node의 partial을 탐색해 slab을 하나 꺼내오는 것을 확인할 수 있다. 만약 이마저도 실패한다면 get_any_partial()을 통해
다른 node의 partial을 탐색해 slab을 하나 꺼내온다.
4-3. 새 slab 할당
만약 이마저도 실패한다면 new_slab_objects()는 다음과 같이
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
}
return freelist;
new_slab()을 통해 새로운 slab을 버디 할당자로부터 할당받는다. 이후 여기서 object를 꺼내 반환한다. 이렇게 하면 slab의 상태는 자연스럽게 partial이 되므로
free 상태의 partial은 따로 관리할 필요가 없어진다.
지금까지의 동작을 정리하면 다음과 같다.
- per-CPU slab에서
freelist를 탐색해 object를 반환한다. - per-CPU가 full 상태여서
freelist가 비어있다면 캐시된 partial slab을 통해 object를 반환한다. - 캐시된 partial slab마저 없다면 해당 노드의 partial을 탐색해 partial slab을 하나 가져온 후 그 안의 object를 꺼내 반환한다.
- 해당 노드의 partial마저 하나도 없다면 다른 노드의 partial을 탐색해 slab을 하나 가져온 후 그 안의 object를 꺼내 반환한다.
- 다른 노드의 partial마저 하나도 없다면 새로운 slab을 버디 할당자로부터 할당받아 object를 꺼내 반환한다.
이렇게 굉장히 복잡하나 정교하게 동작하는 것을 알 수 있다.
-
그림에서 진한 화살표로 표시한 것이 CPU1의
kmem_cache_cpu가 가리키고 있는 slab이고, 연한 화살표로 표시한 것이 CPU2의kmem_cache_cpu가 가리키고 있는 slab이다. ↩
Leave a comment